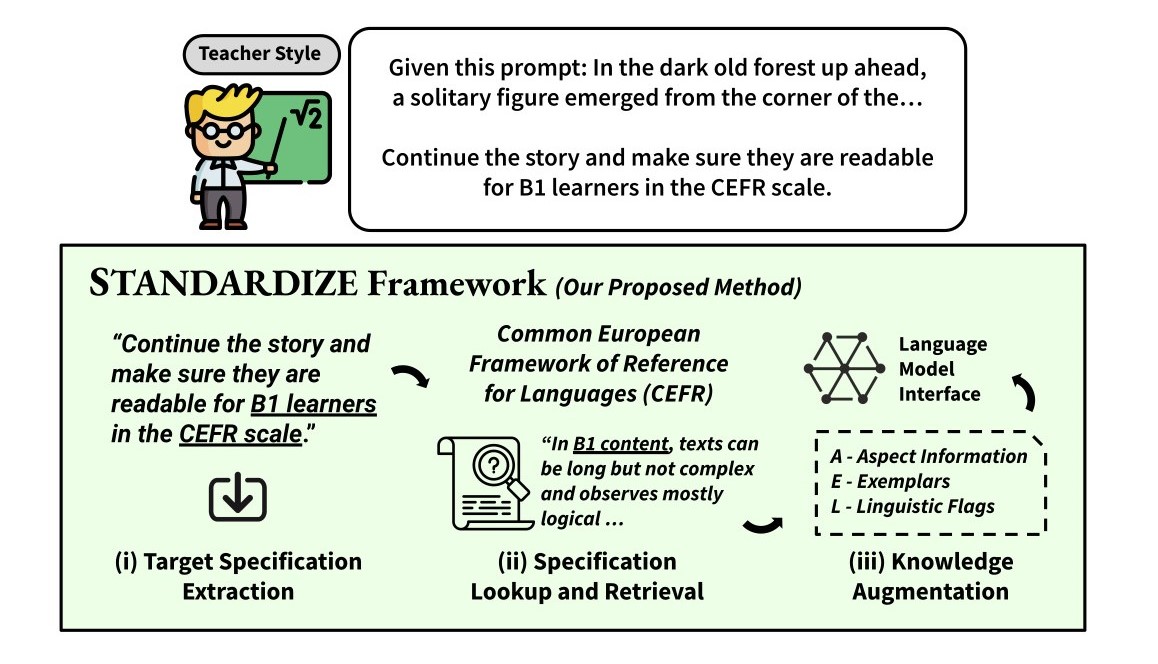
The Standardize framework is a retrieval-style ICL-based framework which aims to guide large language models to generate text content (ex. short stories) that are aligned with expert-defined standards (ex. CEFR or CCS)
What are standards?
Standards are documented guidelines often containing rich detail in describing requirements, specifications, and criteria of a process or a content. These guidelines are defined and continuously improved by experts or interest groups in various domains, such as education, healthcare, and accounting.
Why should LLMs be aligned with expert-defined standards?
Augmenting these expert-defined standards to an LLM to ensure that it can generate text content that aligns to the standards opens a number of advantages. Primarily, using standards will ensure that a model’s internal processes, decision-making, and outputs are consistent and reproducible, which is a prerequisite to building trustworthy AI systems. Human users will also be able to trust LLM-based systems more if they are assured that the technology also adheres to the same standards and rules that human experts follow.
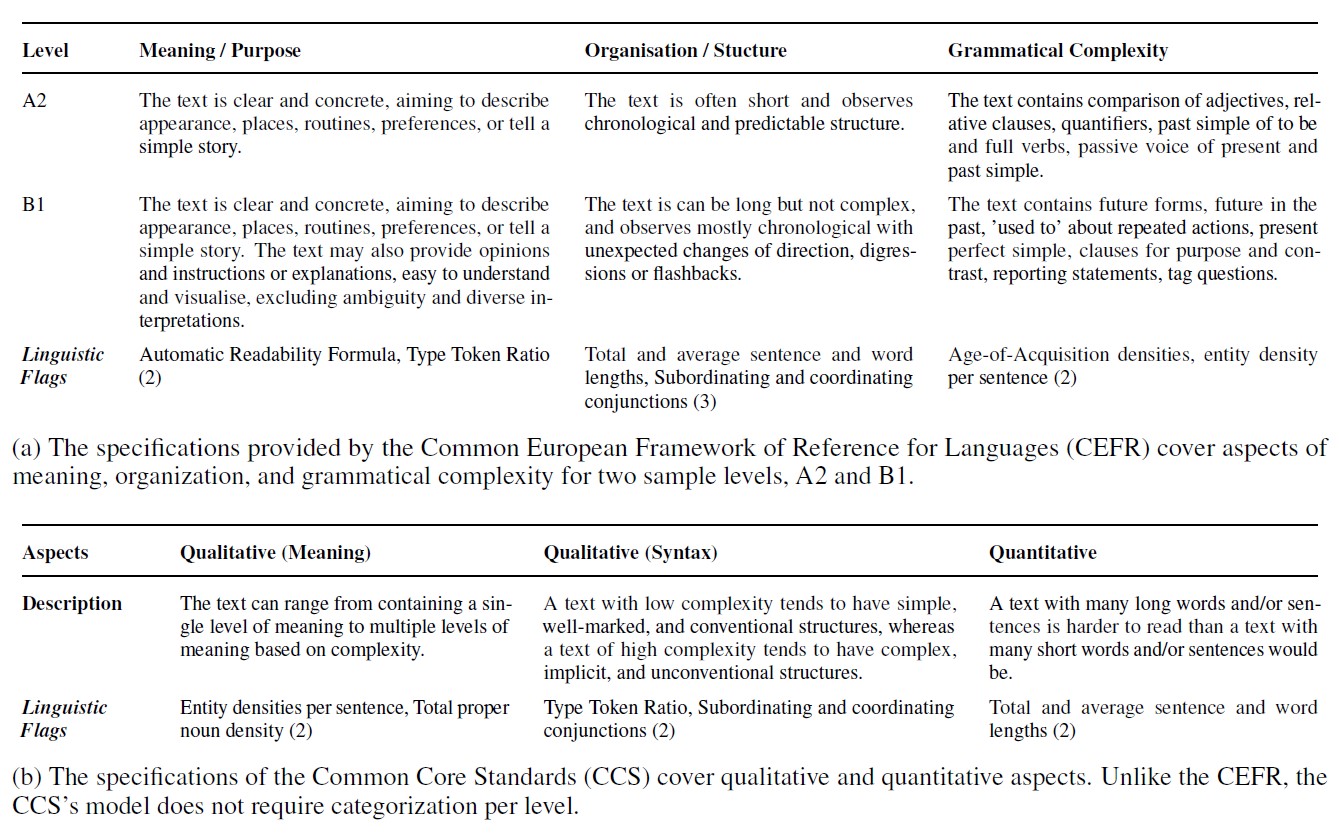
This study focuses on content-based standards used in education and language assessment (see Table below) such as the Common European Framework of Reference for Languages (CEFR) and the Common Core Standards (CCS) which will be augmented into an LLM's text generation process. The alignment with these existing standards for any generated text material is crucial to ensure quality and consistency before being used in classroom settings.
Standardize is a new retrieval-style in-context learning-based framework that exploits the rich information found in standards and transforms this into knowledge artifacts to improve the quality of content produced by generative models.
As seen in the Figure above, the Standardize framework involves a three-part process:
The knowledge augmentation process of Standardize involves the extraction of three forms of knowledge artifacts from the standard itself:

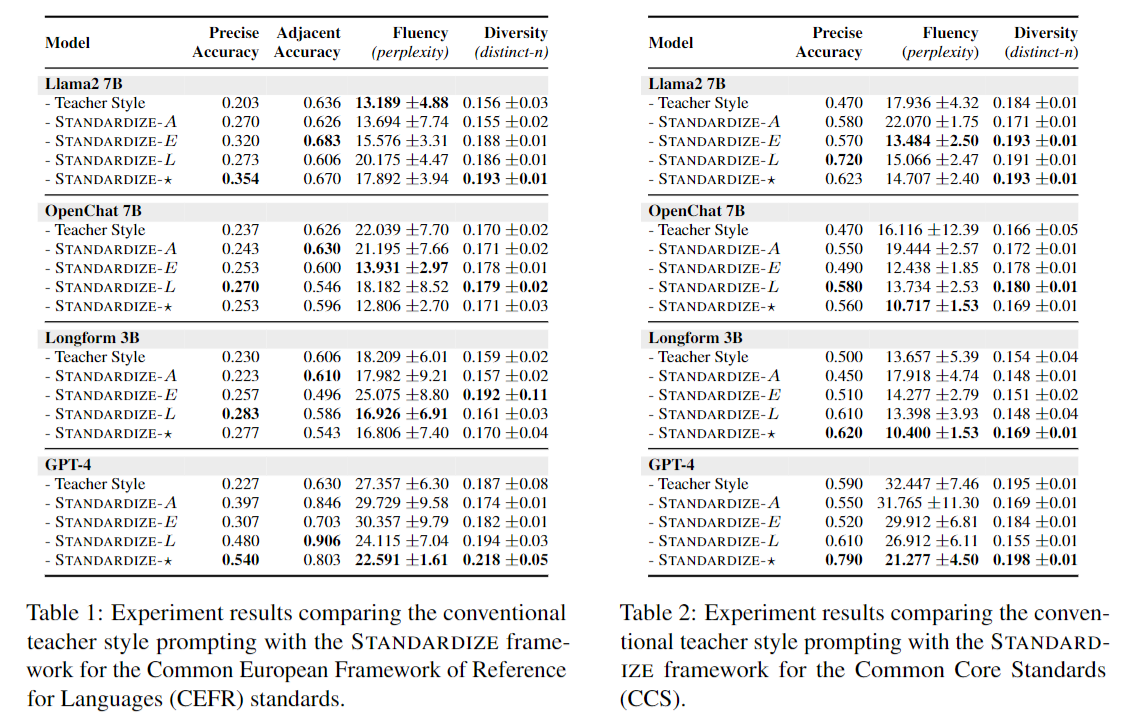
For CEFR, we report a 100% increase in performance with GPT-4 in precise accuracy (from 0.227 → 0.480) and a 43% increase for adjacent accuracy (from 0.630 → 0.906) using the Standardize framework compared to the teacher style method. The open models also gained substantial boosts in performance, such as Longform up by 23%, OpenChat up by 14%, and Llama2 by 58%. In terms of adjacent accuracies, GPT-4 remained the best model for preserving the ordinality of the labels with 0.906.
For CCS, we see a similar pattern where all open and closed models obtained the best performance with Standardize, with boosts ranging from 3% to 45% increase using linguistic signals to refine the generated content toward the target level.
We observe that the general trend of using the best models with linguistic signals produces a more stable distribution across the variables it is explicitly controlling for (e.g., average sentence length or type token diversity), particularly with the CCS standards. We also notice that the distributions using Standardize also produce distributions closer to the mean from their corresponding gold-standard data.
In terms of distributional closeness, using linguistic signals makes the quality of model generations more similar to the linguistic characteristics of the gold standard datasets in CEFR and CCS. Overall, these findings further strengthen the evidence of standard alignment by incorporating specific linguistic variables in the content generation process through the Standardize framework.
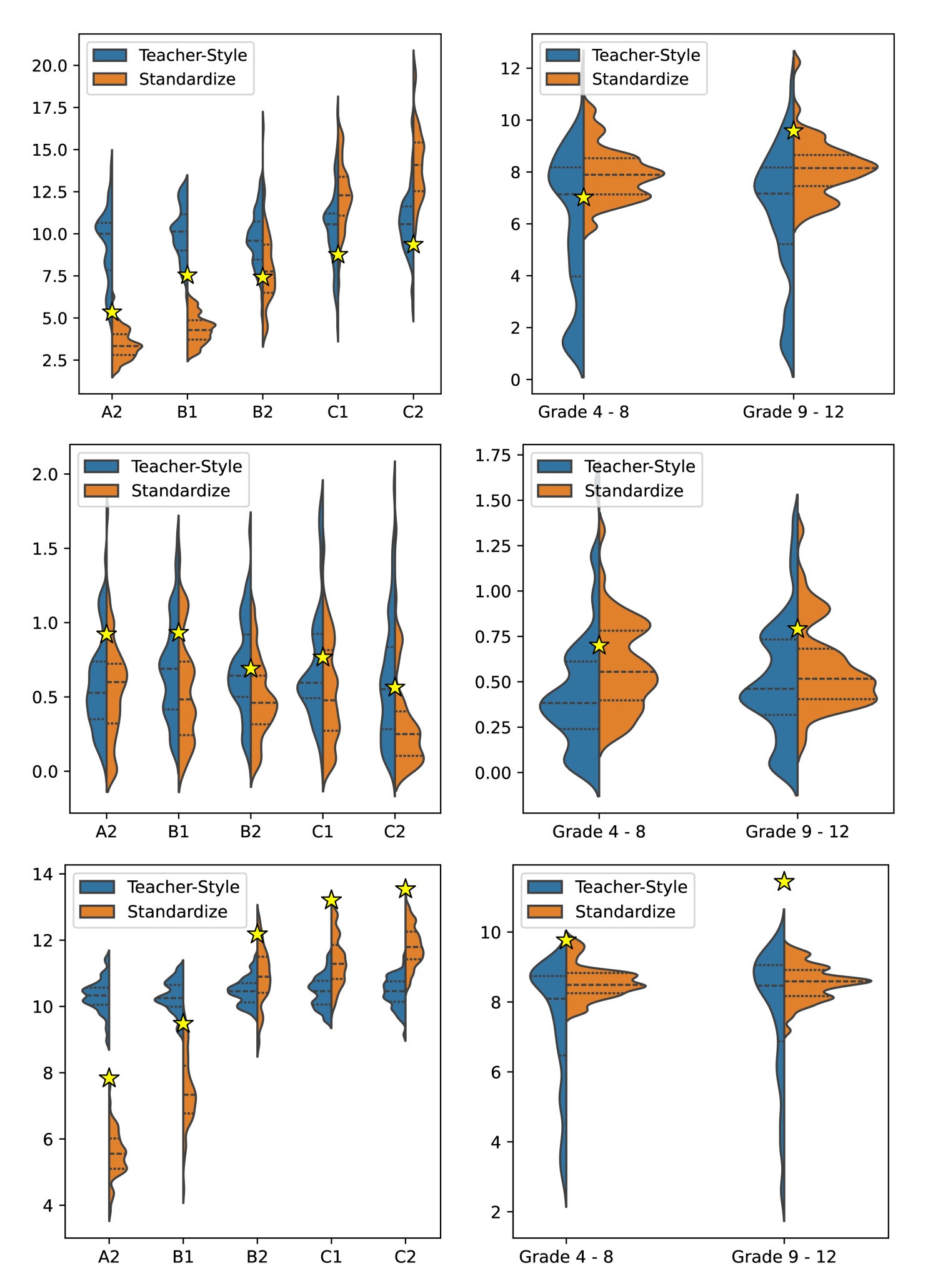
In the case of fluency for models generating CEFR and CCS content, we don't see an obvious tradeoff and report relatively consistent performances with the Standardize setup. The best-performing model is still GPT-4 for both standards and Longform in terms of the open models. On the other hand, with the diversity metric, the most diverse batch of generated content comes from the teacher style method for CCS. But this may be on a case-to-case basis and task-dependent since we do not see the same tradeoff in performance with the CEFR standards in context-assisted story generation.
Ultimately, our experiment procedure is focused on generating text content that aligns with the specified target level with respect to a standard. The standards that we applied in this study, CEFR and CCS, did not explicitly provide information on content creativity and how to measure this. Thus, we posit that creativity may be an interesting angle to explore in future works.
Our experiments with the CEFR and CCS standards showcase an opportunity for the generated texts of language model interfaces such as GPT-4, which are commonly used by educators and teachers, to be aligned with international language proficiency levels. Moreover, showing the effectiveness of the Standardize framework on the aforementioned internationally recognized academic standards used in European and Northern American schools signifies the framework's strong potential for cross-curricula application. Thus, we invite future researchers to explore, validate, and propose derivations of our base framework for their own languages and language-specific standards for content generation.
This work contributes toward the goal of helping educators craft more personalized content for learners using the capabilities of large language models based on an assigned language proficiency level described by a standard. While we present a new task specifically targeted for the NLP community to encourage research in this direction, our results may already be useful for educators by providing context on better methods for generating level or target audience-specific texts by prompting language models using information found in educational standards in the way we proposed.
Works in Complexity Controlled NLG. Research in complexity-controlled generation has been explored in the past, covering diverse facets in terms of text format, level granularity, and task variation. The work of Agrawal and Carpuat (2019) introduced controlling for specific complexity in the machine translation task. The following works of Agrawal and Carpuat (2023) and Ribeiro et al. (2023) explored grade-specific text simplification and summarization using control tokens and reinforcement learning, respectively. Currently, only two works have investigated incorporating CEFR for language learning content generation. Stowe et al. (2022) and Imperial and Madabushi (2023) both made use of CEFR-aligned text for NLG but limited their studies to two levels, A1 and C2.
However, none of these works made use of the actual guideline information found in CEFR during the generation process.
Novelty. The Standardize framework is parallel to the work of Zhou et al. (2023), where a verbalizer is used to transform quantitative constraints into natural language for prompting, as well as the work of Ram et al. (2023) in the lookup and retrieval phase where aspect information is added in the prompt to influence model controllability. In comparison to all the works mentioned, our study’s main novelty is capturing the wholeness of expert-defined standards, prioritizing fine granularity and not just one or two levels, as well as including information that can be represented as artifacts in the content generation process.
@article{imperial2024standardize,
author = {Imperial, Joseph Marvin and Forey, Gail and Tayyar Madabushi, Harish},
title = {{Standardize: Aligning Language Models with Expert-Defined Standards for Content Generation}},
year = {2024},
journal = {arXiv preprint arXiv:2402.12593},
url = {https://arxiv.org/abs/2402.12593}
}